Powershell Portscanner
July 1, 2013 6 Comments
Here is the github link: https://github.com/webstersprodigy/PowerSploit/blob/Portscan/Recon/Invoke-Portscan.ps1. I’ve also put in a pull request on the awesome powersploit project, where hopefully it gets accepted and finds a more permanent home.
The first question is, why another port scanner?
- Similar to why you’d do anything in powershell in a post exploitation scenario :) You never have to write to disk, install software, or run as admin. You can just run this on any box with powershell. Nmap is better in most ways, but it doesn’t fit this bill.
- There are other powershell portscanners out there. Although they are good, in my opinion this is better than all of these existing scripts. For example, the one I linked to isn’t bad in any way, and is in fact the best I found comparable to what I’ve written. But it will take orders of magnitude longer to do scans, it’s not as flexible on the input options, it won’t work in powershell 2.0 out of the box (important for scenarios like I describe below), it doesn’t support ipv6, etc.
- Metasploit has auxilliary portscanners and it is also possible to pivot nmap scans through socks. IMO these are too slow to be usable. This looks promising http://blog.securestate.com/new-meterpreter-extension-released-msfmap-beta/ and it might be a better option if you do all your pwning through meterpreter.
Example 1 – Quick Sweep
You’ve compromised a host and you want to quickly see what other hosts/common ports are available on the same network. Say the sysadmins use RDP to manage the domain, so you’re using RDP on this host too. You don’t want to install any new software just now. My typical workflow is to actually just use -oA, which will output greppable, readable and xml files (sort of like nmap) and I use those to peruse the output. Depending on the number of hosts up, this should take about two minutes or so and it’s checking the top 50 ports.
PS> Import-Module .\Invoke-Portscan.ps1 PS> Invoke-Portscan -hosts "192.168.1.0/24" -oA stuff PS> type .\alltest.gnmap | findstr Open Host: 192.168.1.1 Open Ports: 443,53,22,5000 ...
The module also outputs valid powershell objects, so you can save/pipe these and do the usual operations. Below is answering almost the same question
PS> Import-Module .\Invoke-Portscan.ps1
PS> $a = Invoke-Portscan -hosts "192.168.1.0/24"
PS> #print out only alive hosts
PS> foreach ($h in $a) {if ($h.alive) {$h}}
Hostname : 192.168.1.1
alive : True
openPorts : {443, 53, 22, 5000}
closedPorts : {}
filteredPorts : {80, 23, 21, 3389...}
finishTime : 6/30/2013 11:56:54 AM
...
Example 2: Finding the way in
There are certain questions that can be hard to answer with traditional portscanning (nmap, metasploit, etc.). Say I have code execution on N boxes, but I want to make it to the “jewell box”. I currently can’t access it, but one of my N boxes may be able to access it, or something “closer” to the jewell. This can be common if they open up only certain ports and routes with IP whitelisting in related but separate environments. Behold my awesome visio skills as I demonstrate:
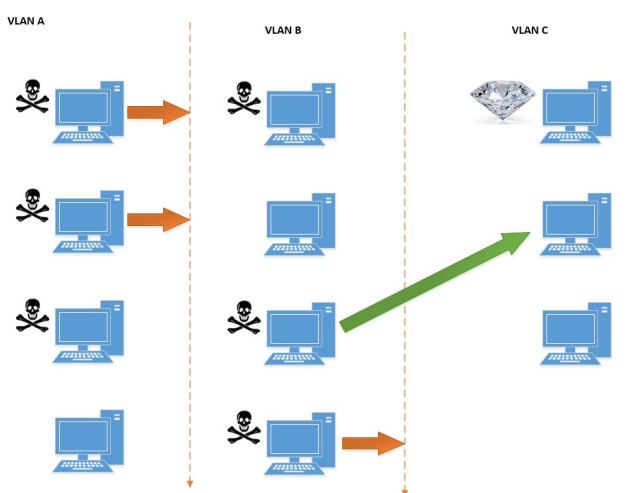
So what we want to do is tell all of our N boxes to scan all the hosts in vlan C, the place with the jewel, and see if any of our N boxes are able to reach it.
We can modify the invoke-powershell.ps1 script slightly to include our command at the end of it, outside of the function. This is similar to the basic usage above. But rather than execute it once, we want to try a portscan on the N hosts we control. Here is the line added to invoke-portscan, where 10.0.10.0 is the “jewel” network.
Invoke-Portscan -Hosts 10.0.10.0/24 -PingOnly -PS "80,443,445,8080,3389" -noProgressMeter
Now on the N hosts we control, we can use remote powershell, if it’s enabled. Here is a one liner that can call our modified script on a box that has remote powershell enabled. This can be easily customized to loop through all of your hosts, depending on how they auth, etc.
$a = Invoke-Command -ComputerName webstersprodigy.cloudapp.net -Port 54932 -Credential lundeen -UseSSL -FilePath C:\psScripts\Invoke-Portscan-mod.ps1
Another way to do this (other than remote powershell) is psexec. This will be executed on every host in hostfile.txt, so we’ll know about any host that can reach our destination. Obviously this is quick and dirty, but it demonstrates the flexibility.
$oFile = "pscan.txt"
$thosts = Get-Content hostfile.txt
foreach ($thost in $thosts)
{
$nPath = "\\$thost\c$\Windows\Temp\stuff.ps1"
copy -Path C:\Users\mopey\Desktop\Invoke-Portscan-mod.ps1 -Destination $nPath
#psexecing powershell directly hangs as described here
#http://www.leeholmes.com/blog/2007/10/02/using-powershell-and-psexec-to-invoke-expressions-on-remote-computers/
$myoutput = PsExec.exe /accepteula \\$thost cmd /c "echo . | powershell.exe -executionpolicy bypass $nPath" 2>&1
foreach($line in $myoutput) {
Write-Host $line
if($line.GetType().Name -eq "string") {
if($line.Contains("True")) {
echo "Source: $thost" >> $oFile
break
}
}
}
remove-item $nPath
}
Conclusion and Lazy Reference
Thanks for reading, and let me know if you try it out, find it useful, have suggestions, etc. For the lazy, here is a reference to the args and some more examples, included with the source
> Get-Help Invoke-Portscan -full
NAME
Invoke-Portscan
SYNOPSIS
Simple portscan module
PowerSploit Function: Invoke-Portscan
Author: Rich Lundeen (http://webstersProdigy.net)
License: BSD 3-Clause
Required Dependencies: None
Optional Dependencies: None
SYNTAX
Invoke-Portscan -Hosts <String[]> [-ExcludeHosts <String>] [-Ports <String>] [-PortFile <String>] [-TopPorts <String>] [-ExcludedPorts <String>]
[-SkipDiscovery] [-PingOnly] [-DiscoveryPorts <String>] [-Threads <Int32>] [-nHosts <Int32>] [-Timeout <Int32>] [-SleepTimer <Int32>] [-SyncFreq <Int32>]
[-T <Int32>] [-GrepOut <String>] [-XmlOut <String>] [-ReadableOut <String>] [-AllformatsOut <String>] [-noProgressMeter] [-quiet] [-ForceOverwrite]
[<CommonParameters>]
Invoke-Portscan -HostFile <String> [-ExcludeHosts <String>] [-Ports <String>] [-PortFile <String>] [-TopPorts <String>] [-ExcludedPorts <String>]
[-SkipDiscovery] [-PingOnly] [-DiscoveryPorts <String>] [-Threads <Int32>] [-nHosts <Int32>] [-Timeout <Int32>] [-SleepTimer <Int32>] [-SyncFreq <Int32>]
[-T <Int32>] [-GrepOut <String>] [-XmlOut <String>] [-ReadableOut <String>] [-AllformatsOut <String>] [-noProgressMeter] [-quiet] [-ForceOverwrite]
[<CommonParameters>]
DESCRIPTION
Does a simple port scan using regular sockets, based (pretty) loosely on nmap
PARAMETERS
-Hosts <String[]>
Include these comma seperated hosts (supports IPv4 CIDR notation) or pipe them in
Required? true
Position? named
Default value
Accept pipeline input? true (ByValue)
Accept wildcard characters? false
-HostFile <String>
Input hosts from file rather than commandline
Required? true
Position? named
Default value
Accept pipeline input? false
Accept wildcard characters? false
-ExcludeHosts <String>
Exclude these comma seperated hosts
Required? false
Position? named
Default value
Accept pipeline input? false
Accept wildcard characters? false
-Ports <String>
Include these comma seperated ports (can also be a range like 80-90)
Required? false
Position? named
Default value
Accept pipeline input? false
Accept wildcard characters? false
-PortFile <String>
Input ports from a file
Required? false
Position? named
Default value
Accept pipeline input? false
Accept wildcard characters? false
-TopPorts <String>
Include the x top ports - only goes to 1000, default is top 50
Required? false
Position? named
Default value
Accept pipeline input? false
Accept wildcard characters? false
-ExcludedPorts <String>
Exclude these comma seperated ports
Required? false
Position? named
Default value
Accept pipeline input? false
Accept wildcard characters? false
-SkipDiscovery [<SwitchParameter>]
Treat all hosts as online, skip host discovery
Required? false
Position? named
Default value False
Accept pipeline input? false
Accept wildcard characters? false
-PingOnly [<SwitchParameter>]
Ping scan only (disable port scan)
Required? false
Position? named
Default value False
Accept pipeline input? false
Accept wildcard characters? false
-DiscoveryPorts <String>
Comma separated ports used for host discovery. -1 is a ping
Required? false
Position? named
Default value -1,445,80,443
Accept pipeline input? false
Accept wildcard characters? false
-Threads <Int32>
number of max threads for the thread pool (per host)
Required? false
Position? named
Default value 100
Accept pipeline input? false
Accept wildcard characters? false
-nHosts <Int32>
number of hosts to concurrently scan
Required? false
Position? named
Default value 25
Accept pipeline input? false
Accept wildcard characters? false
-Timeout <Int32>
Timeout time on a connection in miliseconds before port is declared filtered
Required? false
Position? named
Default value 2000
Accept pipeline input? false
Accept wildcard characters? false
-SleepTimer <Int32>
Wait before thread checking, in miliseconds
Required? false
Position? named
Default value 500
Accept pipeline input? false
Accept wildcard characters? false
-SyncFreq <Int32>
How often (in terms of hosts) to sync threads and flush output
Required? false
Position? named
Default value 1024
Accept pipeline input? false
Accept wildcard characters? false
-T <Int32>
[0-5] shortcut performance options. Default is 3. higher is more aggressive. Sets (nhosts, threads,timeout)
5 {$nHosts=30; $Threads = 1000; $Timeout = 750 }
4 {$nHosts=25; $Threads = 1000; $Timeout = 1200 }
3 {$nHosts=20; $Threads = 100; $Timeout = 2500 }
2 {$nHosts=15; $Threads = 32; $Timeout = 3000 }
1 {$nHosts=10; $Threads = 32; $Timeout = 5000 }
Required? false
Position? named
Default value 0
Accept pipeline input? false
Accept wildcard characters? false
-GrepOut <String>
Greppable output file
Required? false
Position? named
Default value
Accept pipeline input? false
Accept wildcard characters? false
-XmlOut <String>
output XML file
Required? false
Position? named
Default value
Accept pipeline input? false
Accept wildcard characters? false
-ReadableOut <String>
output file in 'readable' format
Required? false
Position? named
Default value
Accept pipeline input? false
Accept wildcard characters? false
-AllformatsOut <String>
output in readable (.nmap), xml (.xml), and greppable (.gnmap) formats
Required? false
Position? named
Default value
Accept pipeline input? false
Accept wildcard characters? false
-noProgressMeter [<SwitchParameter>]
Suppresses the progress meter
Required? false
Position? named
Default value False
Accept pipeline input? false
Accept wildcard characters? false
-quiet [<SwitchParameter>]
supresses returned output and don't store hosts in memory - useful for very large scans
Required? false
Position? named
Default value False
Accept pipeline input? false
Accept wildcard characters? false
-ForceOverwrite [<SwitchParameter>]
Force Overwrite if output Files exist. Otherwise it throws exception
Required? false
Position? named
Default value False
Accept pipeline input? false
Accept wildcard characters? false
<CommonParameters>
This cmdlet supports the common parameters: Verbose, Debug,
ErrorAction, ErrorVariable, WarningAction, WarningVariable,
OutBuffer and OutVariable. For more information, see
about_CommonParameters (http://go.microsoft.com/fwlink/?LinkID=113216).
INPUTS
OUTPUTS
NOTES
version .13
-------------------------- EXAMPLE 1 --------------------------
C:\PS>Invoke-Portscan -Hosts "webstersprodigy.net,google.com,microsoft.com" -TopPorts 50
Description
-----------
Scans the top 50 ports for hosts found for webstersprodigy.net,google.com, and microsoft.com
-------------------------- EXAMPLE 2 --------------------------
C:\PS>echo webstersprodigy.net | Invoke-Portscan -oG test.gnmap -f -ports "80,443,8080"
Description
-----------
Does a portscan of "webstersprodigy.net", and writes a greppable output file
-------------------------- EXAMPLE 3 --------------------------
C:\PS>Invoke-Portscan -Hosts 192.168.1.1/24 -T 4 -TopPorts 25 -oA localnet
Description
-----------
Scans the top 20 ports for hosts found in the 192.168.1.1/24 range, outputs all file formats
RELATED LINKS
http://webstersprodigy.net





